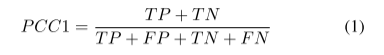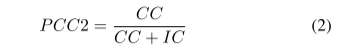Abstract
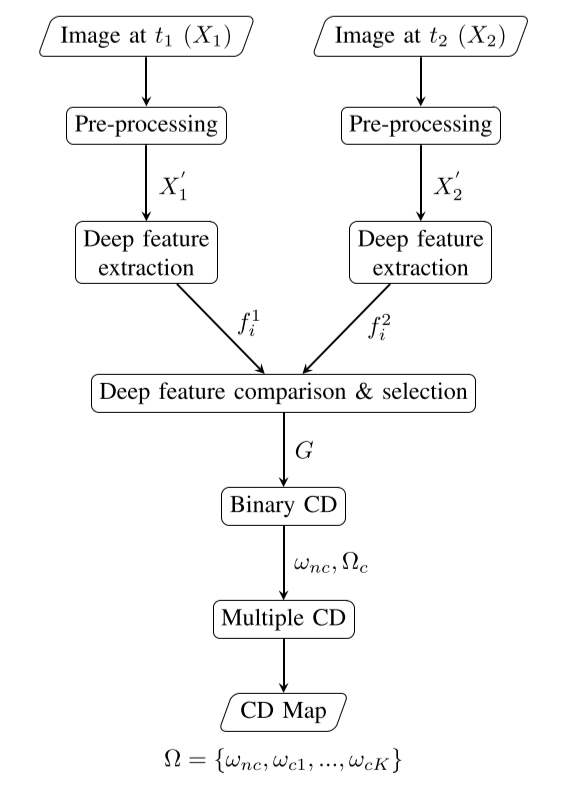
The DCVA(Deep Change Vector Analysis) is change detection methology that based on vector analysis of 'Deep feature extraction' and 'feature comparison'. This model consists of 2 parts. ('Deep feature extraction' and 'feature comparison')
At first, Bi-temporal image pair get through to pretrained ResNet, which for remote sensing image's semantic segmentation. then feature maps of image pair is extracted from the certain layers of ResNet. (Deep feature extraction)
The Feature comparison module compares the creatred 2 feature maps and selects changed vector between of them. The changed vector is represented to binary Change Detection maps.
Summary
Input
Image X1, X2 that have 1024 X 1024 X 4 (RGB+NIR) Those two images must be taken in same sensor.
Preprocessing
The input bitemporal image X1, X2 should be preprocessed for removing distortions.
(1) invert image to obtain radiance value and radiometrci normalization.
(2) orthorectification (정사보정)
(3) Pansharpening (팬샤프닝, 업샘플링)
(4) coregistration
The orthorectification, pansharpening is applied to multispectral bands. However, coregistration is applied to panchromatic band, beacause panchromatic bands' resolution is 4 times higher than multispectral bands.
The pansharpening is applied by Gram-Schmidt method. This preprocessing step mitigate the error that caused by radiometric elements, misalignments, atmosphere.
Deep feature extraction
The preprocessed image pair (X1', X2') separately input to pretrained ResNet Model and the features extracted from certain layers of ResNet. In this paper, Volpi and Tuia is used to pretrained ResNet Model. This model consists of 23 ResNet layers. The 2, 3, 5, 8, 10, 11, 23 layers is used for extraction. Each layers create their own feature map and perform 'Deep feature comaprison' separatly.
Deep feature comparison & selection
The feature map that finished deep feature extraction is subtracted to make difference vector. ( f2i - f1i )
The difference vector is divided spatially to 4 patches. Then variance of vector is computed for each patch.
If the variance become higher, probability of change increases. So we sort all of feature indices by variance in descending order and select certain percentage of feature indices.
This sortation and selection performs in each patch, thus we concatenate all selected feature maps from 4 patches. This result feature map of this selection is called 'deep change hyper vector' or G vector
Change Detection
Compute deep magnitude 'rho'. (r, c is x cord, y cord)
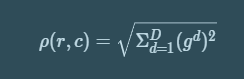
This 'rho' mapped to 1-dimension. By this mapping task, the D-dimension G vector is transformed to 1-dimension and main properties of change can be preserved. We convert 'rho' to 0 or 1 by otsu-threshold.
The '1' represents 'changed vector' and '0' is for 'unchanged vector'. Thus binary change map created.
Result
image 1

image 2

result

Submission result (2021-03-19)

In earthVison21 competetion, The 1st place of Binary change detection!