Abstract
고해상도 표현은 위치에 민감한 vision problem(pose estimation, semantic segmentation)에서 상당히 중요하다. 기존까지 소개된 모델(ResNet, VGGNet, etc.)들은 Convolution과 maxpooling으로 고해상도 이미지가 저해상도로 연결되는 구조다. 이 논문은 전체 과정을 고화질로 유지하면서 이미지를 학습하는 High-Resolution Network를 소개한다.
Summary
HRNet은 두 가지 특성이 있다. 첫째로 고해상도 과정과 저해상도 과정을 병렬적으로 진행한다. 한 해상도 스트림(과정)이 Conv를 진행중일 때 동시에 다른 해상도 스트림도 Conv을 진행한다. 두번째로 반복적으로 두 과정 사이 정보를 주고받는다. 일정 시간 단위 동안 각자 Conv과정을 수행했다가 Stride Conv와 upsampling으로 각 과정 간 정보를 교환한다. 이 특성으로 인해 의미론적으로 풍부하고 공간적으로 정확한 결과를 얻을 수 있다. HRNet은 기존 모델들에 비해 Human Pose detection, Semantic segmentation, Object detection에서 우위를 나타냈다.

HRNet의 진행과정은 다음과 같다. [Fig 1]
(1) 최초 이미지 입력시 two stride-2 3 X 3 convolution 맵을 통과시켜 해상도를 1/4로 줄인다.
(2) 여타 다른 모델들이 레이어를 통과하며 convolution과 maxpooling을 진행해서 해상도를 줄인 것과 달리, 일단 고해상도를 유지하며 convolution을 진행한다.
(3) 기존 고해상도 conv 과정은 유지한 채 Strided convolution으로 중저해상도인 채널 맵을 새로 제작해 conv 과정을 진행한다.
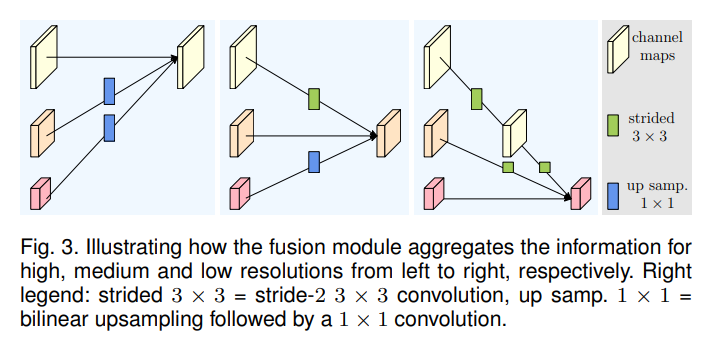
(4) Strided conv로 저해상도 채널 맵을 새로 제작하고, 총 3개의 진행과정 간 정보를 교환한다. 상대적 저해상도 채널 맵은 Up sampling 1X1으로 고해상도 채널 맵에 적용하고, 상대적으로 고해상도 채널 맵은 Strided conv 3X3으로 저해상도 채널 맵에 적용한다. [Fig 2]
(5) 4개 해상도 과정이 병렬적으로 진행됐다면 Representation Head로 출력한다. 출력방법에 따라 Representation Head는 HRNetV1, HRNetV2, HRNetV2p로 구분된다.
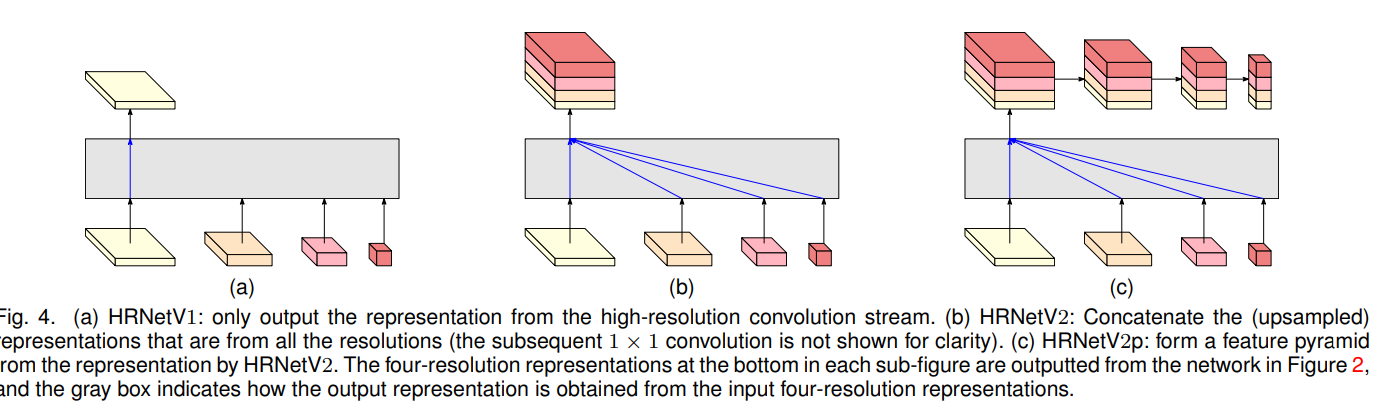
HRNetV1 : 오직 고해상도 스트림 결과물을 출력한다. 다른 3개 스트림 결과물은 무시된다. [Fig 3 (a)]
HRNetV2 : 저해상도 과정을 bilinear upsampling으로 고해상도 과정에 맞게 rescale하고 , 1X1 convolution 필터로 Fully connect 하며 4개 해상도 과정을 concat 한다. [Fig 3 (b)]
HRNetV2p : HRNetV2의 결과물을 downsampling 한다. [Fig 3 (c)]
이 논문에서는 Human Pose estimation(HPE)에 HRNetV1을, Semantic segemntation(SS)에 HRNetV2를, Object detection(OD)에 HRNetV2p를 적용했다. 데이터 셋은 HPE와 OD에는 COCO Dataset를, SS에는 Cityscape와 PASCAL-Context를 사용했다. 실험결과는 본문 참조 (세 분야 모두 SOTA급 성능을 보였다.)
의의, 느낀 점
기존 ResNet, VGGNet, U-Net은 모두 저해상도로 변환하는 과정이 필수 불가결 했지만, 본 HRNet은 고해상도를 유지하면서 Convolution을 진행하는 것이 괄목할만한 성능을 보임을 제시했다.